Week 3, Day 2 (YOLO Model Training and Evaluation)
Welcome to second day (Week 3) of the McE-51069 course.
Before YOLO paper was released, region proposal networks combined with CNNs are usually used for object detection. These RPNs have high precision but takes a lot of time to train. Many attempts has been made to increase the speed of R-CNNs in the mid to late 2010s.
YOLO was introduced in 2015 and showed promise with its speed although it couldn't outperform other detection methods. Later, YOLOv3 was introduced and it made a breakthrough in object detection, outperforming all the object detectors.
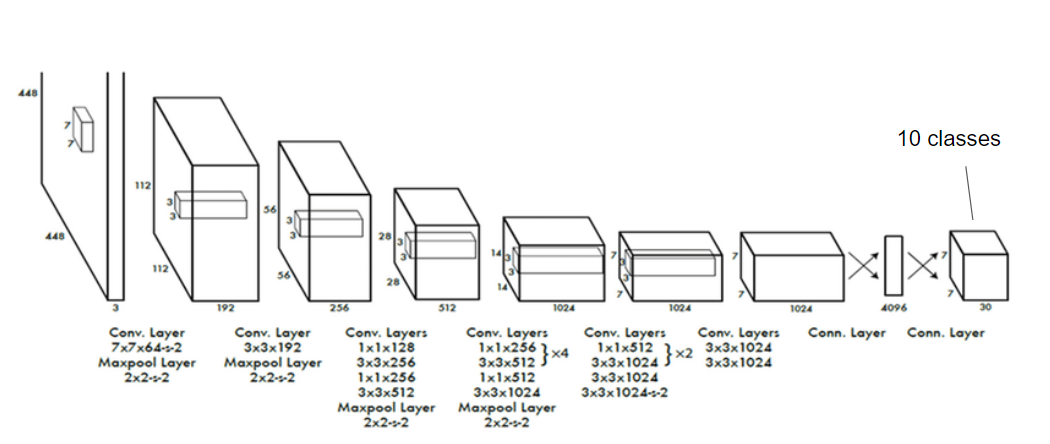
Model Architecture
Convolutional Neural Network process the image the same way we human process the visual signal from our real world. It is a hierarchy process, in which we first detect shape, the structure and then object.
The model architecture of the Convolutional Neural Network is constructed just as the same as to first detect shape in the image, then the structure, and finally the object. By the difference process step in the model, it can be briefly divided into three part.
- Backbone (To detect the basic visual data, such as shape, line)
- Neck (Increase receptive field and connect higher layer feature with lower layer feature.)
- Head (Perform specific task : object detection, semantic segmentation, etc.)
Backbone
In the research field of Deep learning in convolutional neural network, there are many state of the art backbone models that is proved to be useful in many difference field. Because of the basic visual information for all image data are similar, that is, shape, line and edge, so when researcher comes up with some idea of making a model, they often choose one of these state of the art as their backbone.
There are many backbone models available in computer vision field. Some of them are:
Neck
To train a complex model, it is convention to add more layers to the model, while it can increase the model complexity, the model tend to forget early information in the later part of model. To avoid this, Neck layer connect between low level layers with high level layers, so that the early information in the model can last till the end of the model. Also, neck layer increase the receptive field of the model by various method. The most popular method is called the SPP(Spatial Pyramid Pooling) module, where the model use difference kernel size to convolute the output from the backbone. The neck layer for YOLOv4 is the comibination of PANet (Path-Aggregation Net) and SPP(Spatial Pyramid Pooling) module.
Head
The head of the model determine the task of the model. For example, for image classification model, the head would output the number of class in that dataset. While in the object detection, the head would output the bounding box location, the class of that bounding box and its confidence score, etc. The head of the model combine information feed from the neck and make the decision for the model. The head used in YOLO is called the YOLO head, where it performs only once for object detection.
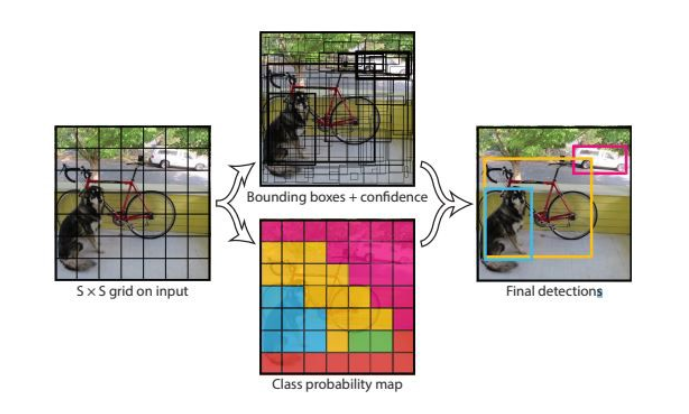
Yolo uses grid cells to identify objects. All grid cells are processed at once: hence, You Look Only Once.

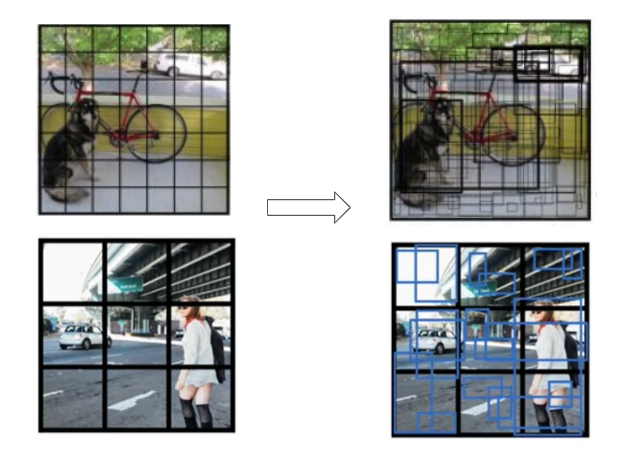
N anchor boxes are then introduced to each grid cell to detect the objects in a grid cell. The boxes can also extend outside of each grid cell if the centroid of the detected object falls into its region

The output from the YOLO layer is determined by objectness, annotation dimensions and class confidence level for each class. Let's assume that we are detecting three classes. Thus, if we have 3x3 grid cells with 2 anchors, the output will be (3 x 3 x 16)
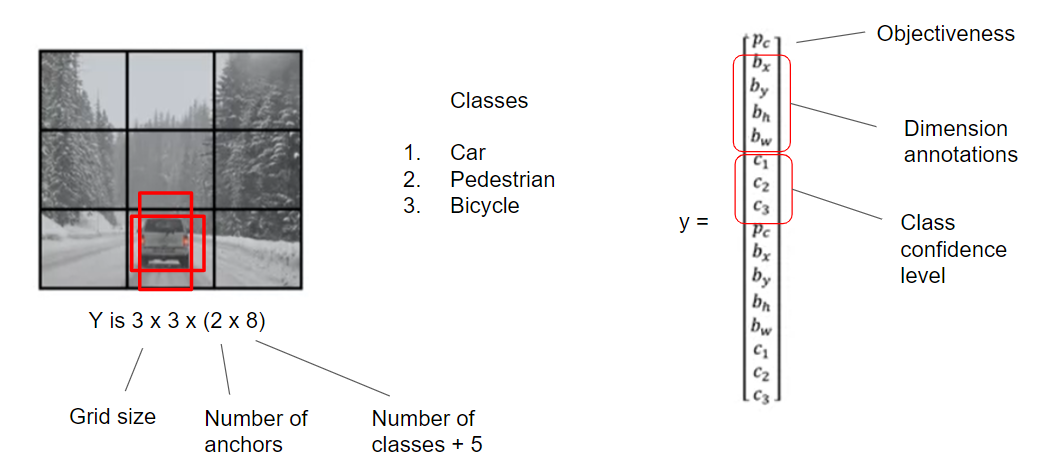
Initially, each grid cell on the image generate n anchor boxes.
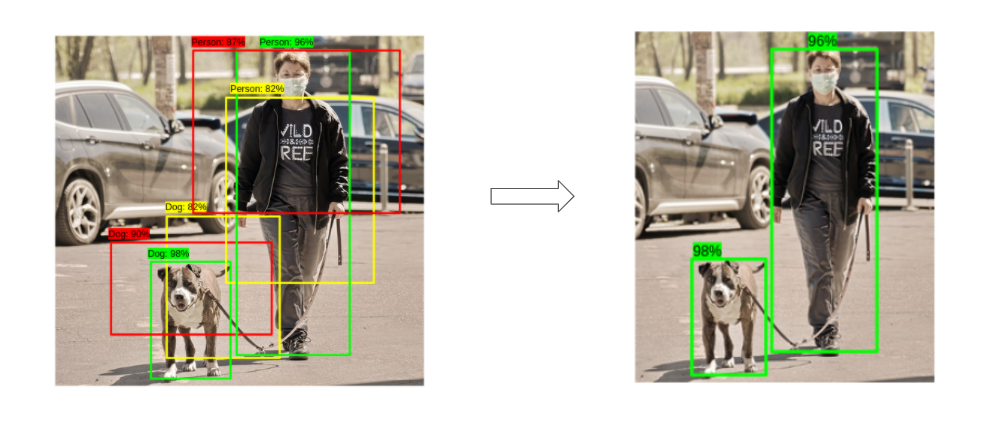
YOLO then performs non-max supression on that anchor boxes to remove the anchor boxes with lower confidence levels.
https://www.coursera.org/lecture/convolutional-neural-networks/yolo-algorithm-fF3O0
https://github.com/ultralytics/yolov5/wiki/Train-Custom-Data#6-visualize
https://paperswithcode.com/method/yolov4
https://medium.com/towards-artificial-intelligence/yolo-v5-explained-and-demystified-4e4719891d69
https://www.coursera.org/lecture/convolutional-neural-networks/anchor-boxes-yNwO0
https://github.com/ultralytics/yolov5
https://engineering.fb.com/2016/08/25/ml-applications/segmenting-and-refining-images-with-sharpmask/